Zerocopy is toolkit that promises safe and efficient abstractions for low-level memory manipulation and casting. While we’ve long done the usual (e.g., testing, documentation, abstraction, miri) and unusual (e.g., proofs, formal verification) to prove to ourselves and our users that we’ve kept our promise of safety, we’ve kept our other promise of efficiency with a less convincing combination of #[inline(always)] and faith in LLVM.
These two promises have increasingly been at odds. As the types and transformations supported by zerocopy have grown more complex, so too have our internal abstractions. Click through our docs into the source code of most of our methods and you will rarely see any immediate occurances of unsafe; we keep the dangerous stuff sequestered away a few function calls down in tightly-scoped “zero cost” abstractions. But are these abstractions actually zero cost?
Well, as of zerocopy 0.8.42 trusting the optimizer requires a little less blind faith. We’ve begun documenting the codegen you can expect from each of zerocopy’s routines in a representative range of circumstances; e.g., for FromBytes::ref_from_prefix:
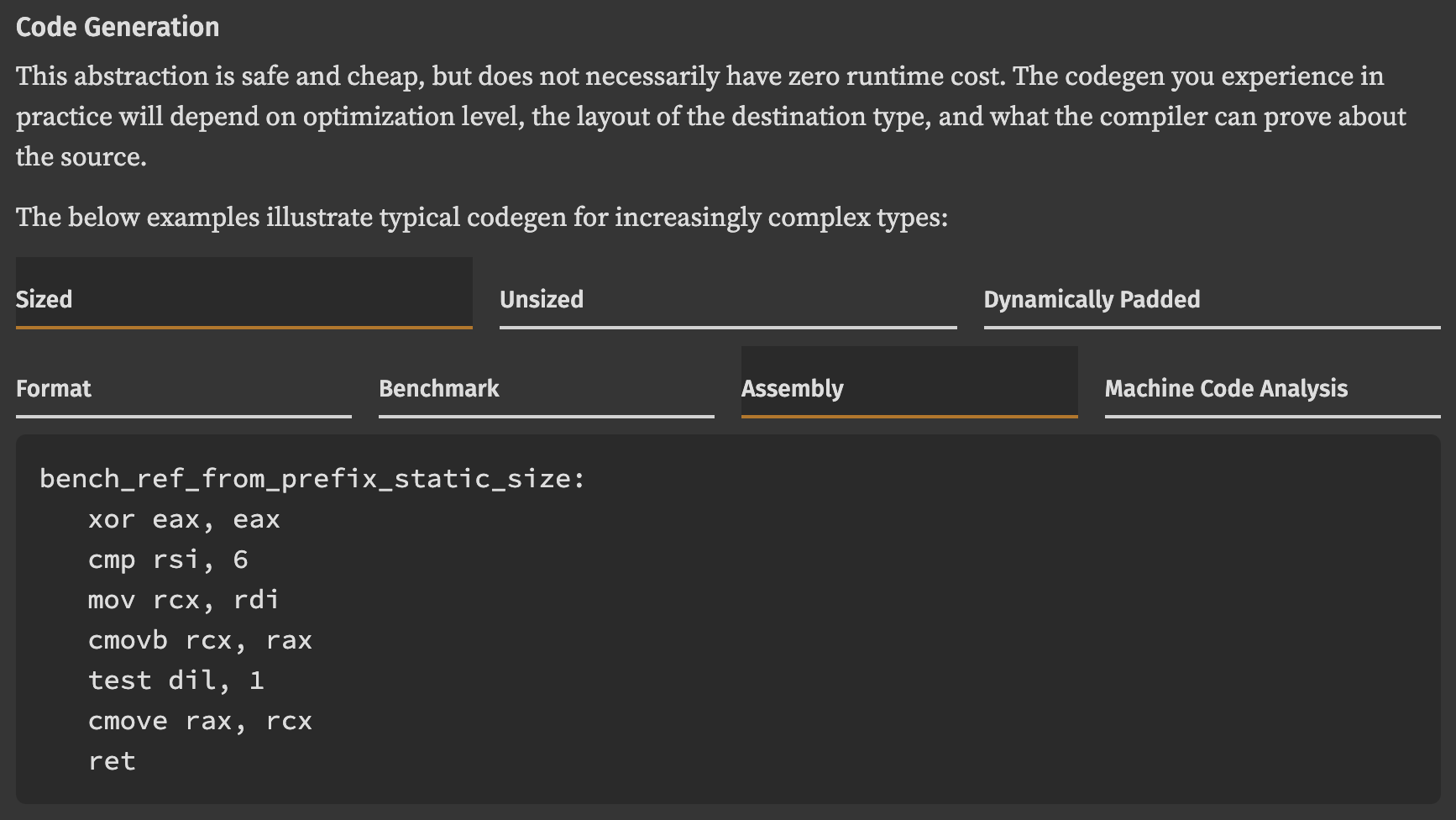
This documentation surfaces the latest addition to our CI pipeline: code generation testing. We’ve populated the benches directory our our repo with a comprehensive set of microbenchmarks. Rather than actually executing these benchmarks on hardware, we use cargo-show-asm to assert that their machine code and analysis matches model outputs checked into our repo. Consequently, we’re able to verify our assumptions about how Rust and LLVM optimize our abstractions, and easily observe how our changes impact codegen.